こんにちは、小澤です。
今回は、分類モデルの評価指標の中でも特に重要な「カテゴリごとの分類精度」「予測確率の正確さ」、そして「混同行列の可視化と分析」について解説していきます。
単に「正解率が何%」というだけでは、分類モデルの性能は十分に評価できません。各カテゴリに対してどの程度正確か、モデルの確信度は信頼できるか、誤分類はどのカテゴリ間で起きているのかといった情報を把握することで、より実践的で信頼性の高いモデルを構築することが可能になります。
今回の内容は、教科書『Pythonによる新しいデータ分析の教科書(第2版)』の4.4.5章「モデルの評価」」(251〜261ページ) の箇所です。
1. 混同行列で全体の分類傾向を把握する
分類結果を視覚的に確認する方法として、混同行列(Confusion Matrix)が広く使われています。混同行列は、予測結果と実際のラベルの関係をマトリクス状に整理したもので、どのクラスをどのクラスと間違えたかが一目でわかります。
| from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression # データの準備 iris = load_iris() X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0) model = LogisticRegression(max_iter=200) model.fit(X_train, y_train) y_pred = model.predict(X_test) # 混同行列の可視化 cm = confusion_matrix(y_test, y_pred) disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=iris.target_names) disp.plot(cmap=”Blues”) plt.title(“Confusion Matrix”) plt.show() |
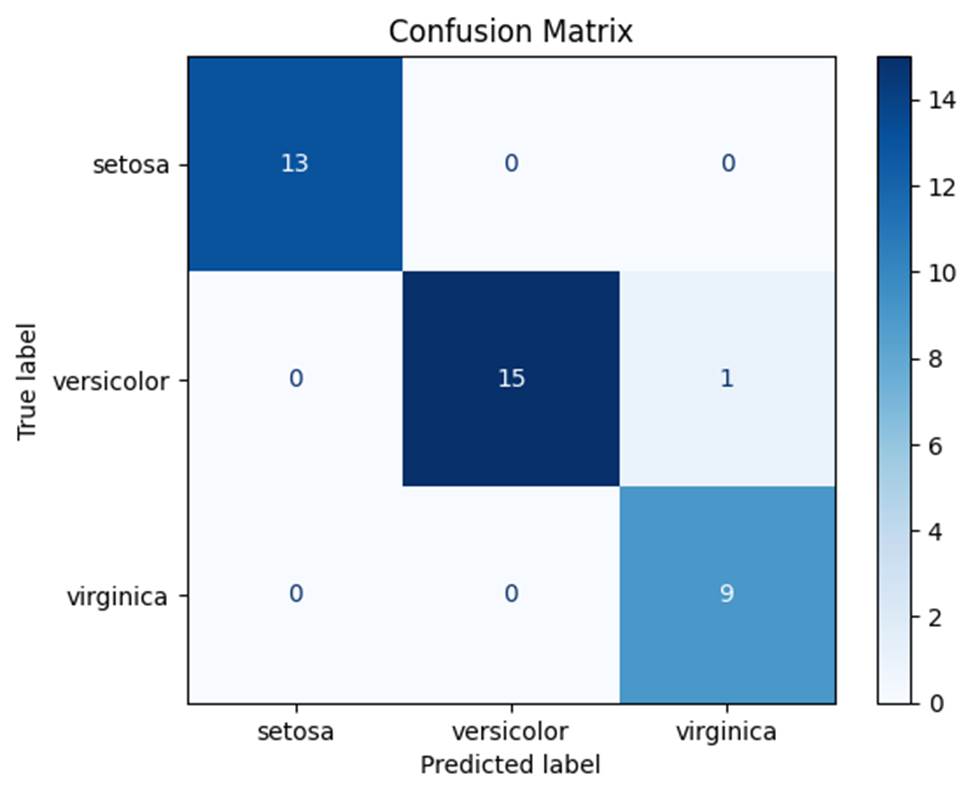
この図から、versicolorとvirginicaの誤分類がどれくらい起きているか、などが分かります。分類の偏りや弱点を発見するのに非常に有効です。
2. カテゴリごとの分類精度:Precision, Recall, F1
モデルの性能は、全体の正解率だけでは不十分です。各カテゴリについてどれだけ正しく識別できたかを示すのが以下の指標です。
- Precision(適合率):そのクラスだと予測されたうち、実際に正解だった割合
- Recall(再現率):実際にそのクラスであったものをどれだけ正しく予測できたか
- F1スコア:PrecisionとRecallのバランス(調和平均)
以下は、scikit-learn ライブラリを使って 分類モデルの評価指標を一覧で出力するものです。 具体的には、次のような情報をクラスごとに表示します。
| from sklearn.metrics import classification_report print(classification_report(y_test, y_pred, target_names=iris.target_names)) |
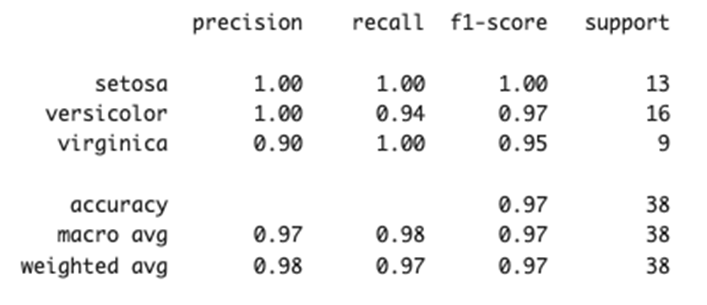
このように、クラスごとの精度や再現率がわかることで、たとえば「virginicaのRecallは高いが、Precisionはやや低い」といった細かい分析が可能になります。
3. 予測確率の信頼度:predict_proba, AUC
多くの分類器では、「クラスラベル」だけでなく、「予測確率(信頼度)」を返すことができます。これにより、モデルが「どの程度自信を持って」分類しているかを把握できます。
| probs = model.predict_proba(X_test) |
これを使って、信頼度が高い予測(例:確率90%以上)だけを取り出して、正解率を確認するといった分析が可能です。
4. ROC曲線とAUCスコア(2クラス分類時)
ROC(Receiver Operating Characteristic)曲線は、予測確率のしきい値を変化させながら、偽陽性率と真陽性率のトレードオフをグラフ化する手法です。
| from sklearn.metrics import roc_curve, roc_auc_score # 2クラス用に変換 y_test_binary = (y_test == 2).astype(int) probs_binary = model.predict_proba(X_test)[:, 2] fpr, tpr, _ = roc_curve(y_test_binary, probs_binary) plt.plot(fpr, tpr, label=”ROC Curve”) plt.plot([0, 1], [0, 1], linestyle=”–“, color=”gray”) plt.xlabel(“False Positive Rate”) plt.ylabel(“True Positive Rate”) plt.title(“ROC Curve”) plt.grid(True) plt.legend() plt.show() print(“AUCスコア:”, roc_auc_score(y_test_binary, probs_binary)) |
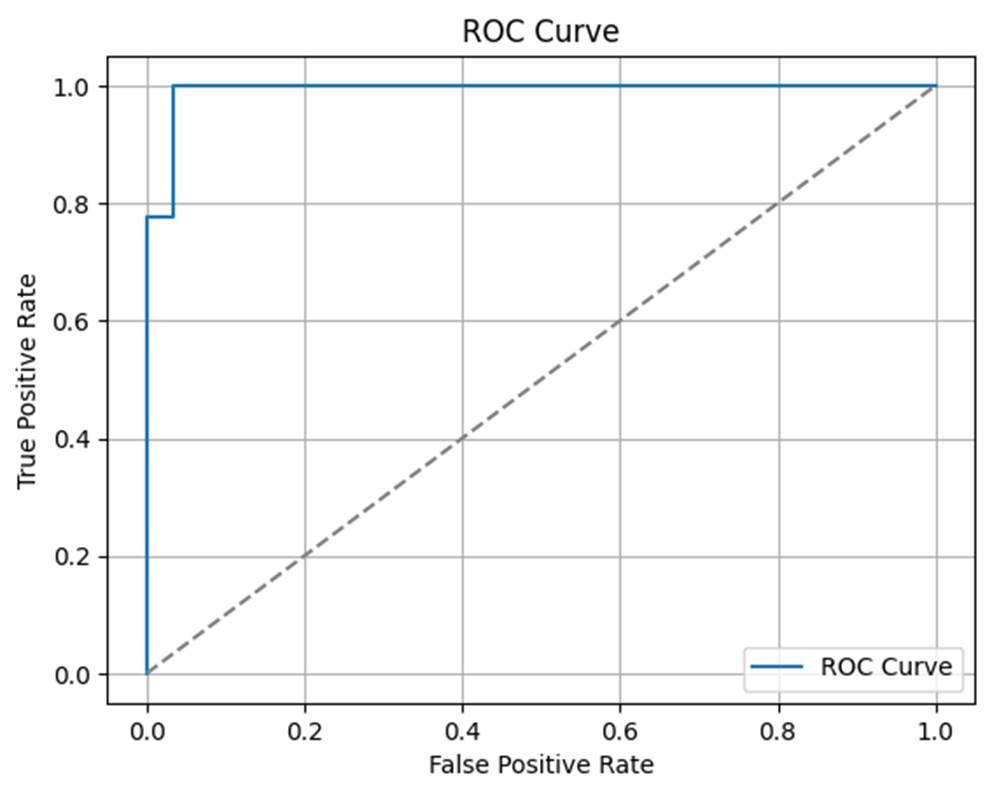
AUC(Area Under Curve) はROC曲線の面積で、最大1.0。1に近いほど分類性能が高いことを示します。
5. 信頼度の分布を見る:ヒストグラム可視化
モデルが「どれくらい確信を持って分類しているか」を可視化するには、最大予測確率の分布を見ると有効です。
| import numpy as np import seaborn as sns confidences = np.max(probs, axis=1) sns.histplot(confidences, bins=20, kde=True) plt.xlabel(“Prediction Confidence”) plt.ylabel(“Count”) plt.title(“Confidence Score Distribution”) plt.grid(True) plt.show() |
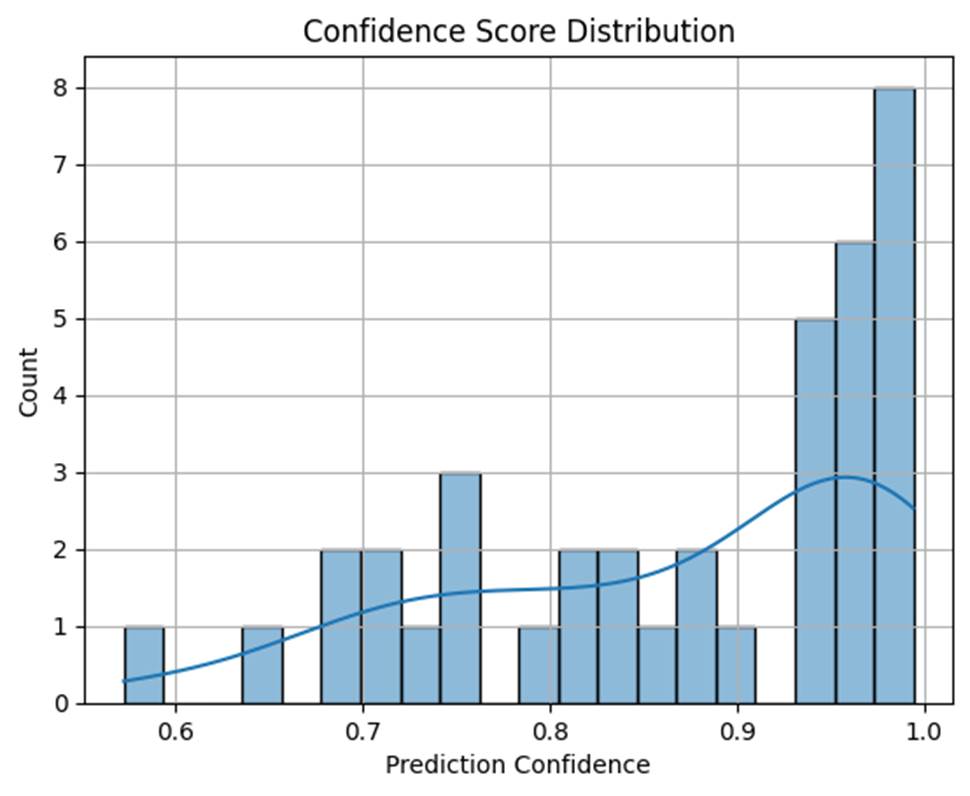
右寄り(0.8~1.0)が多いほど、自信のある予測が多いことを意味します。左側に山が偏っている場合、モデルの出力は不安定かもしれません。
6.まとめ
分類モデルの評価は「Accuracy(正解率)」だけでは不十分です。各カテゴリの精度(Precision, Recall, F1)、モデルの確信度(予測確率)、混同行列による視覚的な誤分類の分析など、複数の観点から総合的に判断することで、実務にも使える信頼性の高いモデルを作ることができます。
- クラスごとの精度を見て、特定のカテゴリに弱いモデルを改善する
- 予測確率が高いデータのみを利用することで、判断の信頼性を高める
- 混同行列から誤分類の傾向を分析し、説明可能なAIとしての改善材料にする
次回は、教師なし学習の代表手法である「クラスタリング(K-meansや階層型クラスタリング)」について解説を進めていきます。ぜひ次回もお楽しみに。