こんにちは、小澤です。
これまで、scikit-learnを中心に、分類・回帰・クラスタリングなど、機械学習の基本的な手法を紹介してきました。scikit-learnはシンプルな構文で高機能な機械学習を実現できる便利なライブラリであり、機械学習の第一歩として最適です。
さらに、より高度なモデル構築や、深層学習(ディープラーニング)を行いたいとき、scikit-learnではやや手が届かない場面も出てきます。そこで今回は、機械学習の中でも特に深層学習に強みを持つライブラリ、TensorFlow(テンソルフロー)とそのラッパーであるKeras(ケラス)を紹介します。
なお、今回の内容は、教科書『Pythonによる新しいデータ分析の教科書(第2版)』の「近ごろの機械学習ライブラリ」(271ページ)の箇所です。
1. TensorFlow / Kerasとは?
TensorFlow(テンソルフロー)は、Googleが開発した機械学習・深層学習のためのオープンソースライブラリです。「ニューラルネットワーク」という、より人間の脳の仕組みに近いモデルを作るのに向いていて、画像認識や音声認識、自然言語処理など、さまざまな高度なAIの基盤として使われています。
一方で、TensorFlowはとても高機能なので、最初に使うには少し複雑で、「コードの書き方が難しい」「覚えることが多い」と少し敷居が高いという課題もありました。
その課題を解決するのが、Keras(ケラス)です。Kerasはもともと独立したライブラリでしたが、現在はTensorFlowに統合され、「tensorflow.keras」として提供されています。簡潔な記述で、モデルの構築、学習、評価、予測までを手軽に行えるため、深層学習の入門としては理想的なツールです。
Kerasを使うと、
- モデルの設計(どんなネットワークにするか)
- 学習の設定(使うアルゴリズムや損失関数)
- 学習の実行や評価
といった一連の流れを少ないコードで分かりやすく実装でき、はじめての人でも数十行のコードで自分だけのAIモデルを作ることができます。
2. Kerasでニューラルネット構築
それでは、Kerasを使ってシンプルなニューラルネットワークを構築し、Irisデータセットを使って分類を行ってみましょう。
使用するライブラリとデータの準備
| import tensorflow as tf from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Input, Dense from tensorflow.keras.utils import to_categorical # データの読み込みと前処理 iris = load_iris() X = iris.data y = to_categorical(iris.target) # One-hotエンコーディング(3クラス分類) # 標準化(平均0、標準偏差1) scaler = StandardScaler() X = scaler.fit_transform(X) # 学習用データとテスト用データに分割(7:3) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) |
モデルの構築と学習
| # モデル構築 model = Sequential([ Input(shape=(4,)), # 入力層(特徴量4つ) Dense(10, activation=’relu’), # 隠れ層1 Dense(10, activation=’relu’), # 隠れ層2 Dense(3, activation=’softmax’) # 出力層(3クラス) ]) # モデルのコンパイル model.compile( optimizer=’adam’, loss=’categorical_crossentropy’, # 多クラス分類用の損失関数 metrics=[‘accuracy’] ) # モデルの学習 model.fit(X_train, y_train, epochs=50, batch_size=8, verbose=1) |
評価と予測
| # 評価 loss, accuracy = model.evaluate(X_test, y_test, verbose=0) print(f”テスト精度: {accuracy:.3f}”) |
実行結果
上記のコードを実行すると以下のようなログが表示されます。
| Epoch 1/50 14/14 ━━━━━━━━━━━━━━━━━━━━ 2s 5ms/step – accuracy: 0.2196 – loss: 1.2509 Epoch 2/50 14/14 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step – accuracy: 0.3505 – loss: 1.1943 … Epoch 50/50 14/14 ━━━━━━━━━━━━━━━━━━━━ 0s 5ms/step – accuracy: 0.9249 – loss: 0.2212 |
これはエポック(学習データを1回すべて使って学習する)の学習結果を表しています。
例えば、「Epoch 50/50」は、全体の50エポックのうち、50回目(最終回)の学習です。
- 14/14:トレーニングデータがバッチサイズ8で区切られ、合計で14バッチあることを示しています(112件の学習データ ÷ 8 = 14)。
- 0s:このエポックの学習にかかった時間(およそ0秒)。
- 5ms/step:1ステップ(バッチあたり)にかかった時間。平均5ミリ秒/バッチ。
- accuracy: 0.9249:このエポックでの学習データに対する正解率(92.49%)。
- loss: 0.2212:このエポックでの損失関数の値。小さいほどモデルの予測が目標に近いことを意味します。
このような出力が、50エポック分、繰り返し表示されています。
- accuracy(精度)は、「どれくらい正解できたか」を示す分類性能の指標で、訓練データに対するモデルの分類の正確さです。92.49%の正解率ということで、かなり良好な結果といえます。
- loss(損失)は、モデル内部の 予測値と正解との誤差を計算したもので、学習の進み具合や最適化の度合いを表します。つまり、モデルがどれくらい間違ったかを数値化したもので、小さいほど誤差が少ないという意味で、0.2212というのは妥当な範囲です。
そして、ログのあとに結果を表示しています。
| テスト精度: 0.911 |
最終的に出力されているテスト精度は、model.evaluate(X_test, y_test) によってテストデータに対するモデルの性能を評価した結果です。
- 0.911 は、テストデータでの分類精度が91.1%だったことを意味します。
- これは「モデルが未知のデータ(学習していないデータ)に対してどれだけうまく分類できるか」の指標であり、実用性を示す重要な数値です。
学習曲線を描画
さらに、loss(損失)やaccuracy(精度)の学習の推移をグラフにすることで、モデルがちゃんと学習できているか、過学習や学習不足になっていないかを視覚的に確認できます。
まず、model.fit()の戻り値(学習履歴)を変数に保存しておきます。
| history = model.fit(X_train, y_train, epochs=50, batch_size=8, verbose=1) |
次に、精度と損失の推移をグラフにします。
| import matplotlib.pyplot as plt # 精度の推移をプロット plt.figure(figsize=(12, 5)) # 精度 plt.subplot(1, 2, 1) plt.plot(history.history[‘accuracy’], label=’Accuracy’) plt.title(‘Training Accuracy over Epochs’) plt.xlabel(‘Epoch’) plt.ylabel(‘Accuracy’) plt.grid(True) plt.legend() # 損失 plt.subplot(1, 2, 2) plt.plot(history.history[‘loss’], label=’Loss’, color=’orange’) plt.title(‘Training Loss over Epochs’) plt.xlabel(‘Epoch’) plt.ylabel(‘Loss’) plt.grid(True) plt.legend() plt.tight_layout() plt.show() |
上記の実行結果が以下のグラフです。左側が精度(accuracy)の推移、右側が損失(loss)の推移です。
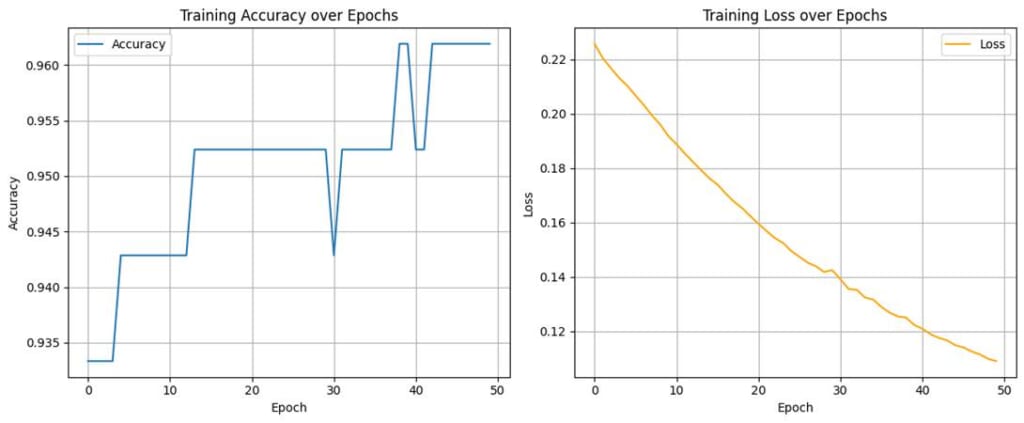
左:Training Accuracy over Epochs(精度の推移)
- 縦軸: 精度(Accuracy)
- 横軸: 学習の繰り返し回数(Epoch)
- 精度はおおむね 0.93〜0.96 の範囲で安定しており、エポック後半でわずかに向上しています。
- 小さな上下はあるものの、精度が大きく落ちることはないため、学習は順調だといえます。
右:Training Loss over Epochs(損失の推移)
- 縦軸: 損失(Loss)
- 横軸: エポック(Epoch)
- 損失はエポックが進むにつれて、なだらかに減少しています。途中で急増するような様子もなく、安定した学習過程を示しています。
- 最後の方で損失が0.1以下に近づいていることから、モデルは誤差を減らしつつ適切に学習しています。
よって、精度、損失ともに改善傾向が明確に見られる良好な学習曲線といえます。
3. TensorFlow/Kerasの強みと注意点
主なメリット
- 柔軟で強力なモデル構築:CNN、RNN、注意機構など高度なモデルも扱えます。
- GPU対応:大規模データや深いネットワークでも高速に学習できます。
- 豊富なドキュメントとチュートリアル:Google公式の教材が多数あります。
- Kerasによる簡潔な記法:初学者でも直感的にモデルを構築できます。
注意点
- 小規模なタスクや浅いモデルにはオーバースペックになることがあります。
- 学習データの前処理や形状の合わせ方に注意が必要です。
- 構文はわかりやすいが、内部の挙動を理解するには少し時間がかかるかもしれません。
4. まとめ
今回は、TensorFlow / Kerasを使ってシンプルなニューラルネットワークの実装方法を紹介しました。TensorFlowは、画像認識や音声認識といった深層学習タスク、大規模なデータ処理、エッジデバイスやモバイルアプリへの展開(TensorFlow Lite)など、本格的なAI開発に強みを持つライブラリです。画像認識や自然言語処理、異常検知、生成モデル(GAN)など、scikit-learnでは表現しきれない複雑なパターンの学習にも適しています。さらに、Kerasは直感的に使えるため、初心者にも扱いやすく、深層学習への入り口としても人気があります。
次回は、同じく人気の高い深層学習ライブラリPyTorch(パイトーチ)を紹介します。PyTorchは「コードの柔軟性」や「研究開発向けの使いやすさ」で注目されており、TensorFlowとはまた違った特長を持っています。ぜひ次回もお楽しみに。